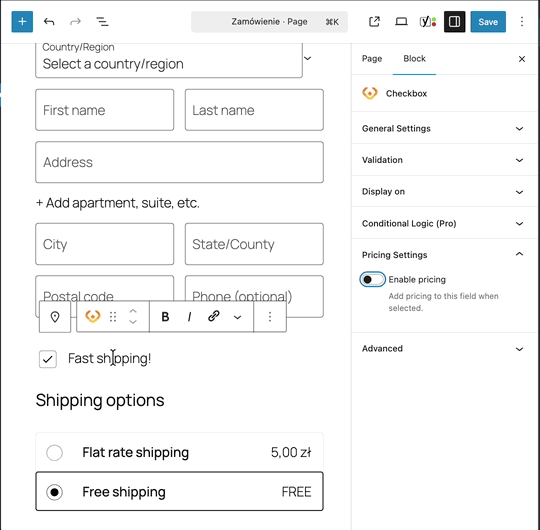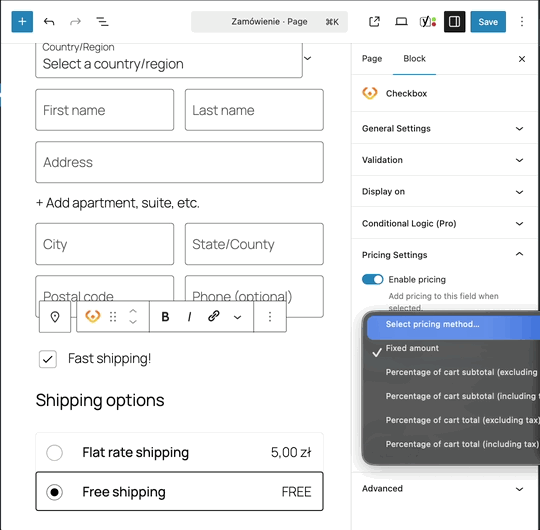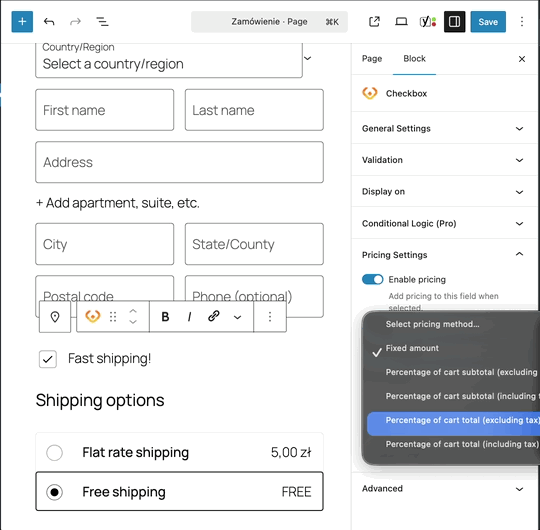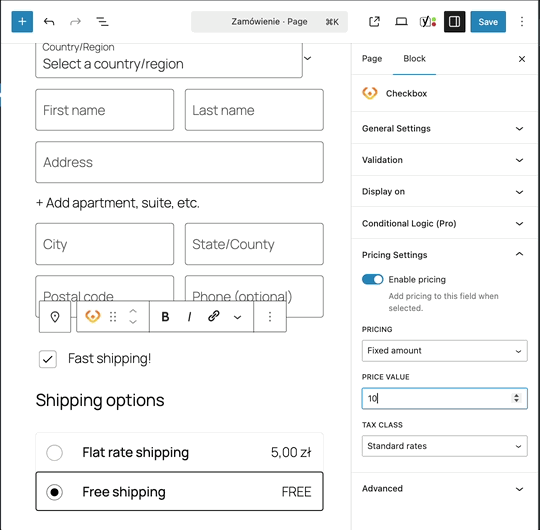
Découvrez Super Speedy | Super Speedy Imports, un plugin WordPress, conçu pour optimiser, avec vélocité, vos importations de données. Simplifiez vos tâches, gagnez du temps, et améliorez l'efficacité de votre site. Idéal pour ceux qui recherchent la performance, sans compromis. Adoptez-le, et transformez votre expérience utilisateur.
Comment télécharger Super Speedy | Super Speedy Imports
Accès illimité
Obtenez Super Speedy | Super Speedy Imports et 19616 autres produits en vous inscrivant au Club
Obtenir ce produit seulement avec mises à jour illimitées
plugins premium
Nous ne sommes pas affiliés avec Super Speedy | Super Speedy Imports ni avec ses développeurs ou propriétaires. Veuillez lire l'avis complet en pied-de-page.
COMMENT ÇA MARCHE
Mises à jour automatiques avec le plugin Club WPress
Regardez comment installer et mettre à jour vos plugins et thèmes WordPress en UN CLIC directement depuis votre tableau de bord.
Fonctionnalités principales de Super Speedy | Super Speedy Imports
Importation Rapide de Contenu : Permet d’importer rapidement de grandes quantités de contenu, y compris des articles, des pages et des produits.
Compatibilité WooCommerce : Optimisé pour importer des produits dans WooCommerce, y compris les variations de produits et les attributs.
Support des Fichiers CSV et XML : Accepte les fichiers CSV et XML pour une flexibilité maximale dans le format des données d’importation.
Planification des Importations : Possibilité de planifier des importations automatiques à intervalles réguliers.
Mapping des Champs Personnalisés : Permet de mapper les champs des fichiers d’importation aux champs personnalisés de WordPress.
Gestion des Erreurs : Inclut des outils pour identifier et corriger les erreurs d’importation.
Interface Utilisateur Intuitive : Offre une interface facile à utiliser pour configurer et gérer les importations.
Support Multilingue : Compatible avec les plugins de traduction pour importer du contenu dans plusieurs langues.
Options de Mise à Jour : Possibilité de mettre à jour le contenu existant lors de l’importation de nouvelles données.
Historique des Importations : Garde un enregistrement des importations passées pour référence future.
Quoi de neuf (Journal des modifications - Changelog) dans Super Speedy | Super Speedy Imports version 2.66.0
= 2,66,0 (8 juillet 2026) =
Nouveau : l’écran Run Now a été repensé. Pendant qu’une importation s’exécute, vous voyez désormais chaque niveau avec sa propre progression et activité des ouvriers, un pourcentage global et un minuteur écoulé, un panneau de configuration système, un débit de pic en direct et une console moteur en direct codée par couleur.
Nouveau : à la fin d’une importation, le popover passe à un écran de finition avec une table d’efficacité par étape (durée, mémoire de pic, débit), un panneau de vélocité affichant le débit moyen et une répartition complète du nombre (publications créées et mises à jour, méta des publications, termes, relations, taxonomies), des totaux d’auto-correction et d’intégrité, un téléchargement de résumé d’exportation et un lien pour consulter les posts/produits mis à jour.
Nouveau : définir la visibilité des Caractéristiques et du catalogue sur la carte d’importation, une colonne Mise en vedette (1/oui) et une colonne Visibilité du catalogue (« visible », « catalogue », « recherche » ou « cachée ») dans les informations de publication. Ces éléments se combinent avec le statut de stock dans les termes de « product_visibility » du produit. Cartographier la taxonomie de la « product_visibility » les supprime directement pour l’ensemble de l’importation.
Amélioré : les produits importés en rupture de stock bénéficient désormais du terme « en rupture de stock » de WooCommerce, améliorant les performances et éliminant le besoin de lancer des sauvegardes après des publications.
Corrigé : lorsque le slug (post_name) n’est pas cartographié, les produits partageant un titre reçoivent désormais leurs suffixes de slug ‘-2’/’-3′ dans l’ordre des lignes CSV à chaque fois, au lieu d’un ordre qui pourrait varier entre les exécutions.
= 2,65,0 (8 juillet 2026) =
Nouveau : un bouton « Charger les importations d’échantillons » dans le panneau droit permet de configurer les importations d’échantillons prêtes à l’exécution en un seul clic, il enregistre les taxonomies des produits (catégories, marques, couleurs), copie le CSV de l’échantillon dans votre dossier de téléchargements, et crée la configuration d’importation. Pro comprend une importation simple de 1000 produits et une importation complète ; L’édition gratuite inclut l’importation simple. Rien n’est importé tant que vous n’en choisissez pas un et appuyez sur Exécuter maintenant.
Nouveau : une fois qu’une importation a été lancée, son résumé affiche un lien « Supprimer tous les produits chargés par cette importation (x) », où x est le numéro qui sera supprimé. Il déplace chaque produit importé créé dans la corbeille (identique au CLI « – supprimer tout »), ainsi que le lien existant « Voir les produits affectés ».
Corrigé : relancer une importation via le navigateur ne supprime plus les catégories, tags et attributs des produits. L’importateur du navigateur (AJAX) exécute désormais exactement le même code par étape que la CLI, de sorte que les deux ne peuvent plus s’éloigner.
Corrigé : l’importation complète (produits variables) ne tombe plus en panne dans le navigateur avec un « parsererror » opaque. Les erreurs d’étape apparaissent désormais dans le journal de débogage à l’écran afin de pouvoir les diagnostiquer.
Corrigé : les boutons « Tout afficher » par section répondent désormais immédiatement après la création d’une nouvelle importation, sans avoir besoin de rafraîchissement de page.
Corrigé : les importations du navigateur (AJAX) enregistrent désormais le bon nombre de lignes et exécutent les détails dans l’historique des importations, à la fois dans le résumé en haut de la page et dans la liste d’historiques. Auparavant, une exécution AJAX affichait 0 ligne (ou « NA ») tandis que la même exécution d’importation via CLI était correcte.
Changement : après la fin d’une importation par navigateur, le résumé d’importation en haut de la page se met à jour automatiquement (dernière date d’exécution, lignes et total des exécutions) au lieu d’avoir besoin d’un rafraîchissement de page.
Changement : la menu déroulante de la méthode de mappage de champs affiche désormais « PHP » (ou « PHP (PRO Only) » dans l’édition gratuite) au lieu de la plus longue « PHP Function », qui débordait la mise en page.
Modifié : les requêtes de base de données qui font référence aux tables de plugins par leur nom passent désormais par ‘$wpdb->prepare()’ en utilisant le marque-place d’identifiant ‘ %i’, afin de satisfaire à la vérification WordPress.org Plugin pour l’édition gratuite. Cela porte la version minimale de WordPress à 6.2, où le « %i » a été introduit.
Corrigé : la graine de la table d’aide à la séquence à l’activation lie désormais ses valeurs de ligne via « $wpdb->prepare() » au lieu de construire la chaîne SQL à la main.
= 2.64.0 (8 juillet 2026) =
Nouveau : la maintenance automatique post-importation actualise désormais toute la boutique WooCommerce, elle recense les termes (y compris les attributs des produits), efface les passages produits et boutiques, et régénère les tables de recherche des produits et attributs qui gèrent le tri boutique et les filtres de navigation en couches. Auparavant, seuls les décomptes de catégories et de tags étaient mis à jour. Fonctionne à la fois pour les importations de CLI et de navigateur (AJAX).
Nouveau : dans l’édition gratuite, le menu « Super Speedy » de haut niveau affiche désormais une page de présentation des plugins au lieu d’un écran vide.
= 2.63.0 (7 juillet 2026) =
Nouveau : une édition gratuite de Super Speedy Imports. Les sections payantes restent visibles mais sont clairement marquées « PRO Only » (avec un lien vers la mise à niveau), ce qui permet de voir exactement ce que la version Pro apporte.
Corrigé : les décomptes de catégories et d’étiquettes sont désormais recomptés automatiquement à la fin de chaque importation, pour les exécutions CLI et navigateurs (AJAX). Auparavant, ils pouvaient afficher 0 jusqu’à ce que vous fassiez un « recomptage des termes de WP » manuel.
Corrigé : une erreur d’exécution dans l’une de vos fonctions PHP personnalisées (par exemple, en référant une colonne CSV qui n’existe pas) arrête désormais l’importation du navigateur avec une erreur claire à l’écran, au lieu de sembler s’exécuter mais de ne rien importer.
Corrigé : importer une configuration sauvegardée sur une importation déjà chargée ne duplique plus chaque champ.
Nouveau : une confirmation animée « Import Complete » à la fin d’une importation par navigateur, et appuyer sur Échap ferme désormais la boîte de dialogue de progression une fois l’import terminé.
= 2.62.0 (7 juillet 2026) =
Nouveau : l’identifiant unique de l’élément possède désormais sa propre section pliable avec un menu déroulant prédéfini et un résumé en temps réel de ce sur quoi il correspond, donc la plupart des utilisateurs n’ont jamais besoin du constructeur de champs. Les produits par défaut sont « SKU », les publications « Titre du post » (avec « Titre du post + catégorie » également proposé), et « Personnalisé » élargit le panneau pour combiner les champs à la main. La section identifiant indique maintenant que pour chaque modèle, auparavant il n’apparaissait que pour WooCommerce.
Changement : le créateur personnalisé ne liste plus tous les champs postmeta. Il propose une liste blanche courte (« _sku » plus des clés GTIN courantes) vérifiées à bas prix pour son existence, ce qui le rend rapide sur les grands sites. Ajoutez n’importe quelle autre clé à la main. Extensible via le filtre « ssi_uid_postmeta_whitelist ».
Modifié : Options supplémentaires est désormais repliée par défaut, pour signaler que ces réglages ne sont généralement pas nécessaires.
Corrigé : les *Show Allbuttons ont désormais un fond blanc uni au lieu d’apparaître grisé ou transparent.
= 2,61,0 (3 juillet 2026) =
Corrigé : une régression des performances (introduite dans la version non publiée 2.59.0) qui a ralenti les importations fraîches importantes. Une importation fraîche de 50 000 produits, qui prenait environ 16 minutes, se termine maintenant en environ 30 secondes. La correction et la correction de sécurité 2.59.0 pour importation interrompue sont restées inchangées.
= 2.60.0 (3 juillet 2026) =
Nouveau : une édition gratuite de Super Speedy Imports est désormais disponible sur WordPress.org.
= 2,59,0 (2 juillet 2026) =
Corrigé : une importation interrompue en cours d’insertion de nouveaux éléments à un stade spécifique (insert-posts) avec des causes d’interruption spécifiques (par exemple, une mort hors mémoire, un délai d’extinction de l’hôte ou l’arrêt du processus) pourrait en théorie, lors de la prochaine exécution, créer des posts zombies.
= 2,58,0 (27 juin 2026) =
Nouveau : une méthode de *Value*mapping, aux côtés de *CSV Champ et *Fonction PHP*. Choisissez **Valeur* pour définir une constante pour un champ/postmeta/taxonomie sur chaque ligne — pas besoin de PHP. Sélectionner Valeur avec une case vide efface ce champ. Cela remplace également la fonction interne par ligne utilisée par l’importateur pour tamponner chaque article, de sorte qu’une importation normale basée sur un champ n’évalue plus du tout de PHP.
Changement : le code de fonction PHP personnalisé est désormais isolé dans un seul fichier. Si un scanner de malwares (par exemple Imunify) met en quarantaine ou vide ce fichier, seules les fonctions personnalisées sont affectées, les importations normales basées sur champs continuent de fonctionner avec un message clair, au lieu qu’un fichier central soit cassé.
Changement : une erreur d’exécution dans l’une de vos fonctions PHP personnalisées annule désormais l’importation et rapporte l’erreur, au lieu de continuer avec des données vides/incorrectes.
= 2,57,0 (23 juin 2026) =
Nouveau : l’identifiant unique d’élément peut désormais combiner plusieurs champs, n’importe quel mélange de champs de publication (Titre, Slug, GUID), de clés postmeta (par exemple SKU) et de taxonomies (par exemple « product_cat », « pa_color »). Les éléments correspondent lorsque *tous les champs choisis sont égaux. Cela résout le cas courant « même SKU, couleur/taille différente » où un SKU n’est pas unique. La correspondance correspond aux données déjà contenues par votre catalogue, donc les réimportations mettent à jour les articles existants au lieu de les dupliquer, même pour des produits que SSI n’a pas créés.
Nouveau : si un identifiant composite ne peut pas distinguer deux lignes (ou deux éléments existants), l’importation s’annule désormais avec un rapport clair listant les lignes affectées, au lieu de mettre à jour silencieusement le mauvais élément.
Nouveau : lorsque l’identifiant inclut une taxonomie, les modes d’importation qui sautent la résolution taxonomique (« Mettre à jour les prix/postméta seulement », « Rafraîchir les images seulement ») sont désactivés, car l’appariement de la taxonomie nécessite que l’étape de résolution des termes s’exécute.
Changement : les anciens identifiants de fonction PHP et de colonne brute CSV ont été supprimés, une valeur calculée à partir de la ligne CSV ne peut pas être comparée aux éléments existants, ce qui était la cause principale du duplicate-on-update. Choisissez plutôt des champs post / postmeta / taxonomie.
Note : les identifiants composites ne sont pas encore pris en charge pour les produits variables / parentaux synthétisés qui utilisent un seul SKU à cet endroit.
= 2,56 (23 juin 2026) =
Un « post_name » mappé (slug produit) est désormais importé mot pour mot au lieu d’être écrasé par un slug dédupliqué dérivé du titre.
Corrigé : choisir un champ comme identifiant unique d’élément correspond désormais à vos éléments existants sur la clé postmeta native de ce champ (par exemple, SKU sur ‘_sku’) au lieu de la clé privée de SSI. Auparavant, utiliser le champ SKU comme identifiant ne permettait pas de trouver les produits créés en dehors de SSI (manuellement ou par un autre importateur), donc une réimportation dupliquait tous les produits existants au lieu de la mise à jourEn train de le faire. Les importations existantes sont migrées automatiquement ; Aucune reconfiguration nécessaire.
...
>
Rejoignez le Club maintenant !
Accédez à 19616 produits pour seulement €10,90 par mois.
Découvrez , un plugin WordPress innovant. Simplifiez votre processus de paiement, personnalisez les champs de commande, et ajustez les prix dynamiquement....
Avec Webba Booking, nous simplifions la gestion de vos rendez-vous et réservations sur WordPress. Profitez d'une interface intuitive, des fonctionnalités...
Découvrez le plugin WordPress "", qui enrichit votre expérience sociale. Ajoutez des hashtags à vos publications, facilitez la recherche de contenu,...
Nous utilisons des cookies pour vous garantir la meilleure expérience sur notre site web. En continuant la navigation sur ce site, vous accepter leur utilisation.